Over the past 8–10 years, I’ve run into the same set of issues again and again when deploying Node.js applications to AWS Lambda—especially those built with the popular Express.js framework.
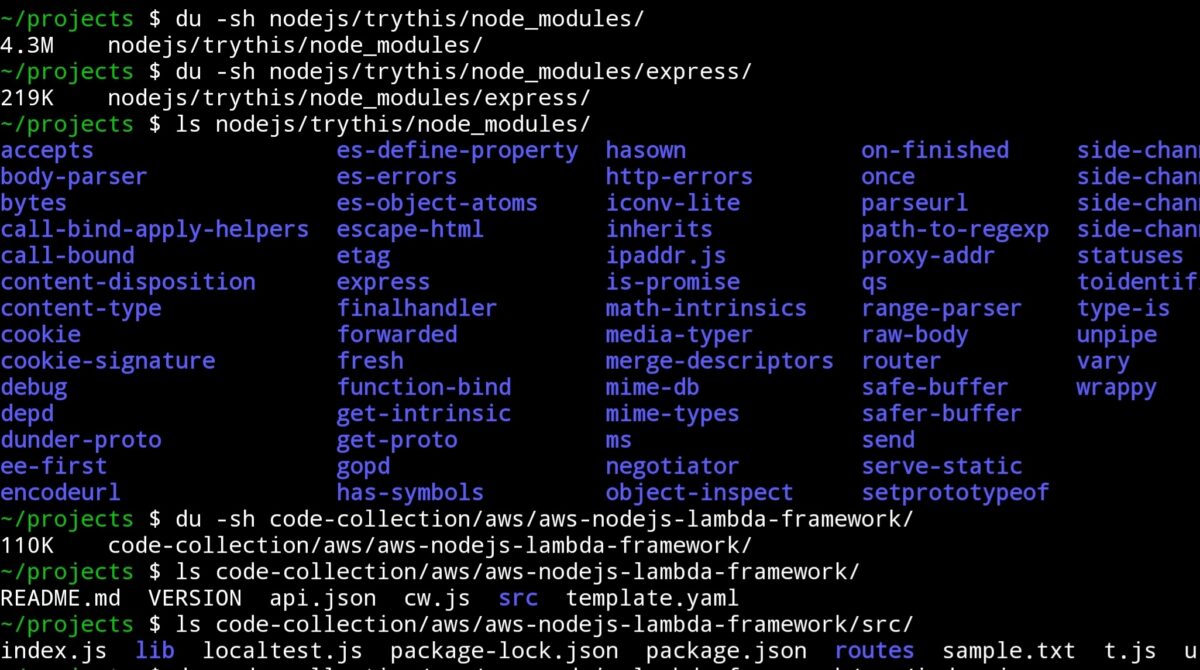
While Express is just 219 KB, the dependency bloat is massive—often exceeding 4.3 MB. In the world of serverless, that’s a serious red flag. Every time I had to make things work, it involved wrappers, hacks, or half-hearted workarounds that made deployments messy and cold starts worse.
Serverless and Express Don’t Mix Well
In many teams I’ve worked with, the standard approach was a big, monolithic Express app. And every time developers tried to work in parallel, we hit code conflicts. This often slowed development and created complex merge scenarios.
When considering serverless, we often used the “one Lambda per activity” pattern—cleaner, simpler, more manageable. But without structure or scaffolding, building and scaling APIs this way felt like reinventing the wheel.
A Lean Framework Born From Frustration
During a professional break recently, I decided to do something about it. I built a lightweight, Node.js Lambda framework designed specifically for AWS:
🔗 Try it here – http://bz2.in/njsfra
Base size: ~110 KB
After build optimization: Can be trimmed below 60 KB
Philosophy: Lazy loading and per-endpoint modularity
This framework is not just small—it’s structured. It’s optimized for real-world development where multiple developers work across multiple endpoints with minimal overlap.
Introducing cw.js: Scaffolding From OpenAPI
To speed up development, the framework includes a tool called cw.js—a code writer utility that reads a simplified OpenAPI v1.0 JSON definition (like api.json) and creates:
Routing logic
A clean project structure
Separate JS files for each endpoint
Each function is generated as an empty handler—ready for you to add business logic and database interactions. Think of it as automatic boilerplate—fast, reliable, and consistent.
You can generate the OpenAPI definition using an LLM like ChatGPT or Gemini. For example:
Prompt:
Assume the role of an expert JSON developer.
Create the following API in OpenAPI 1.0 format:
[Insert plain-language API description]
Why This Architecture Works for Teams
No more code conflicts: Each route is its own file
Truly parallel development: Multiple devs can work without stepping on each other
Works on low-resource devices: Even a smartphone with Termux/Tmux can run this (see: tmux video)
The Magic of Lazy Loading
Lazy loading means the code for a specific API route only loads into memory when it’s needed. For AWS Lambda, this leads to:
✅ Reduced cold start time
✅ Lower memory usage
✅ Faster deployments
✅ Smaller, scalable codebase
Instead of loading the entire API, the Lambda runtime only parses the function being called—boosting efficiency.
Bonus: PHP Version Also Available
If PHP is your stack, I’ve built something similar:
PHP Micro Framework: https://github.com/jthoma/phpmf
Stub Generator Tool: https://github.com/jthoma/phpmf-api-stub-generator
The PHP version (cw.php) accepts OpenAPI 3.0 and works on similar principles.
Final Thoughts
I built this framework to solve my own problems—but I’m sharing it in case it helps you too. It’s small, fast, modular, and team-friendly—ideal for serverless development on AWS.
If you find it useful, consider sharing it with your network.