The Unofficial Challenge: Why Automate Kubernetes on AWS?
Ever wondered if you could spin up a fully functional Kubernetes cluster on AWS EC2 with just a few commands? Four years ago, during my DevOps Masters Program, I decided to make that a reality. While the core assignment was to learn Kubernetes (which can be done in many ways), I set myself an ambitious personal challenge: to fully automate the deployment of a minimal Kubernetes cluster on AWS EC2, from instance provisioning to node joining.
Manual Kubernetes setups can be incredibly time-consuming, prone to errors, and difficult to reproduce consistently. I wanted to leverage the power of Infrastructure as Code (IaC) to create a repeatable, disposable, and efficient way to deploy a minimal K8s environment for learning and experimentation. My goal wasn’t just to understand Kubernetes, but to master its deployment pipeline, integrate AWS services seamlessly, and truly push the boundaries of what I could automate within a cloud environment.
The full github link: https://github.com/jthoma/code-collection/tree/master/aws/aws-cf-kubecluster
The Architecture: A Glimpse Behind the Curtain
At its core, my setup involved an AWS CloudFormation template (managed by AWS SAM CLI) to provision EC2 instances, and a pair of shell scripts to initialize the Kubernetes control plane and join worker nodes.
Here’s a breakdown of the key components and their roles in bringing this automated cluster to life:
AWS EC2: These are the workhorses – the virtual machines that would host our Kubernetes control plane and worker nodes.
AWS CloudFormation (via AWS SAM CLI): This is the heart of our Infrastructure as Code. CloudFormation allows us to define our entire AWS infrastructure (EC2 instances, security groups, IAM roles, etc.) in a declarative template. The AWS Serverless Application Model (SAM) CLI acts as a powerful wrapper, simplifying the deployment of CloudFormation stacks and providing a streamlined developer experience.
Shell Scripts: These were the crucial “orchestrators” running within the EC2 instances. They handled the actual installation of Kubernetes components (kubeadm, kubelet, kubectl, Docker) and the intricate steps required to initialize the cluster and join nodes.
When I say “minimal” cluster, I’m referring to a setup with just enough components to be functional – typically one control plane node and one worker node, allowing for basic Kubernetes operations and application deployments.
The Automation Blueprint: Diving into the Files
The entire orchestration was handled by three crucial files, working in concert to bring the Kubernetes cluster to life:
template.yaml (The AWS CloudFormation Backbone): This YAML file is where the magic of Infrastructure as Code happens. It outlines our EC2 instances, their network configurations, and the necessary security groups and IAM roles. Critically, it uses the UserData property within the EC2 instance definition. This powerful property allows you to pass shell commands or scripts that the instance executes upon launch. This was our initial entry point for automation.
You can view the `template.yaml` file on GitHub [here](https://www.google.com/search?q=https://github.com/jthoma/code-collection/blob/master/aws/aws-cf-kubecluster/template.yaml).kube-bootstrap.sh (The Instance Preparation Script): This script is the first to run on our EC2 instances. It handles all the prerequisites for Kubernetes: installing Docker, the kubeadm, kubectl, and kubelet binaries, disabling swap, and setting up the necessary kernel modules and sysctl parameters that Kubernetes requires. Essentially, it prepares the raw EC2 instance to become a Kubernetes node.
You can view the `kube-bootstrap.sh` file on GitHub [here](https://www.google.com/search?q=https://github.com/jthoma/code-collection/blob/master/aws/aws-cf-kubecluster/kube-bootstrap.sh).kube-init-cluster.sh (The Kubernetes Orchestrator): Once kube-bootstrap.sh has laid the groundwork, kube-init-cluster.sh takes over. This script is responsible for initializing the Kubernetes control plane on the designated master node. It then generates the crucial join token that worker nodes need to connect to the cluster. Finally, it uses that token to bring the worker node(s) into the cluster, completing the Kubernetes setup.
You can view the `kube-init-cluster.sh` file on GitHub The Deployment Process: sam deploy -g in Action
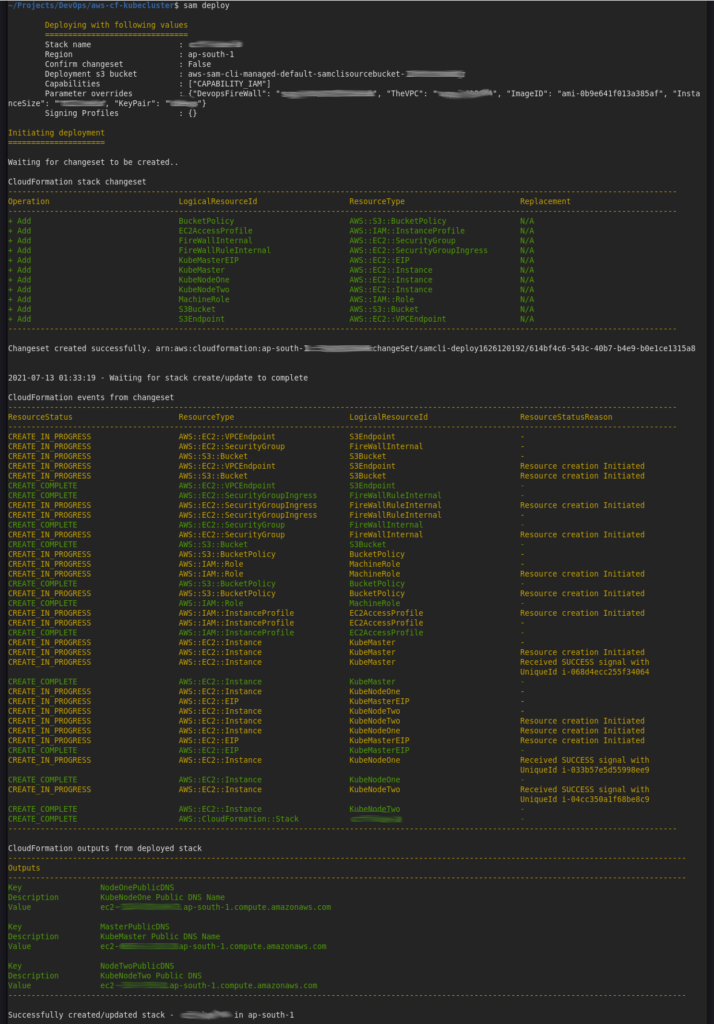
The entire deployment process, from provisioning AWS resources to the final Kubernetes cluster coming online, is kicked off with a single, elegant command from the project’s root directory:
sam deploy -g
The -g flag initiates a guided deployment. AWS SAM CLI interactively prompts for key parameters like instance types, your AWS EC2 key pair (for SSH access), and details about your desired VPC. This interactive approach makes the deployment customizable yet incredibly streamlined, abstracting away the complexities of direct CloudFormation stack creation. Under the hood, SAM CLI translates your template.yaml into a full CloudFormation stack and handles its deployment and updates.
The “Aha!” Moment: Solving the Script Delivery Challenge
One of the most persistent roadblocks I encountered during this project was a seemingly simple problem: how to reliably get kube-bootstrap.sh and kube-init-cluster.sh onto the newly launched EC2 instances? My initial attempts, involving embedding the scripts directly into the UserData property, quickly became unwieldy due to size limits and readability issues. Other complex methods also proved less than ideal.
After several attempts and a bit of head-scratching, the elegant solution emerged: I hosted both shell scripts in a public-facing downloads folder on my personal blog. Then, within the EC2 UserData property in template.yaml, I simply used wget to download these files to the /tmp directory on the instance, followed by making them executable and running them.
This approach proved incredibly robust and streamlined. It kept the CloudFormation template clean and manageable, while ensuring the scripts were always accessible at launch time without needing complex provisioning tools or manual intervention. It was a classic example of finding a simple, effective solution to a tricky problem.
Lessons Learned and Key Takeaways
This project, born out of an academic requirement, transformed into a personal quest to master automated Kubernetes deployments on AWS. It was a journey filled with challenges, but the lessons learned were invaluable:
Problem-Solving is Key: Technical roadblocks are inevitable. The ability to iterate, experiment, and find creative solutions is paramount in DevOps.
The Power of Infrastructure as Code (IaC): Defining your infrastructure programmatically is not just a best practice; it’s a game-changer for reproducibility, scalability, and disaster recovery.
Automation Principles: Breaking down complex tasks into manageable, automated steps significantly reduces manual effort and error.
AWS CloudFormation and UserData Versatility: Understanding how to leverage properties like UserData can unlock powerful initial setup capabilities for your cloud instances.
Persistence Pays Off: Sticking with a challenging project until it works, even when faced with frustrating issues, leads to deep learning and a huge sense of accomplishment.
While this was a fantastic learning experience, if I were to revisit this project today, I might explore using a dedicated configuration management tool like Ansible for the in-instance setup, or perhaps migrating to a managed Kubernetes service like EKS for production readiness. However, for a hands-on, foundational understanding of automated cluster deployment, this self-imposed challenge was truly enlightening.
Last time when I ran it the console was as follows:
Conclusion
This project underscored that with a bit of ingenuity and the right tools, even complex setups like a Kubernetes cluster can be fully orchestrated and deployed with minimal human intervention. It’s a testament to the power of automation in the cloud and the satisfaction of bringing a challenging vision to life.
I hope this deep dive into my automated Kubernetes cluster journey has been insightful. Have you embarked on similar automation challenges? What unique problems did you solve? Share your experiences in the comments!

