In any web application project, selecting the optimal database is crucial. Each project comes with unique requirements, and the final decision often depends on the data characteristics, the application’s operational demands, and future scaling expectations. For my most recent project, choosing a database meant evaluating a range of engines, each with strengths and trade-offs. Here, I’ll walk through the decision-making process and the architecture chosen to meet the application’s unique needs using AWS services.
Initial Considerations
When evaluating databases, I focused on several key factors:
- Data Ingestion and Retrieval Patterns: What type of data will be stored, and how will it be accessed or analyzed?
- Search and Select Complexity: How complex are the queries, and do we require complex joins or aggregations?
- Data Analysis Needs: Will the data require post-processing or machine learning integration for tasks like sentiment analysis?
The database engines I considered included MariaDB, PostgreSQL, and Amazon DynamoDB. MariaDB and PostgreSQL are widely adopted relational databases known for reliability and extensive features, but DynamoDB is particularly designed to support high-throughput applications on AWS, making it a strong candidate.
The Project’s Data Requirements
This project required the following data structure:
- Data Structure: Each row was structured as JSON, with a maximum record size of approximately 1,541 bytes.
- Attributes: Each record included an asset ID (20 chars), user ID (20 chars), a rating (1 digit), and a review of up to 1,500 characters.
- Scale Expectations: Marketing projections suggested rapid growth, with up to 100,000 assets and 50,000 users within six months, resulting in a peak usage of about 5,000 transactions per second. Mock Benchmarks and Testing
To ensure scalability, I conducted a benchmarking exercise using Docker containers to simulate real-world performance for each database engine:
- MariaDB and PostgreSQL: Both performed well with moderate loads, but resource consumption spiked sharply under simultaneous requests, capping at around 50 transactions per second before exhausting resources.
- Amazon DynamoDB: Even on constrained resources, DynamoDB managed up to 24,000 requests per second. This performance, combined with its fully managed, serverless nature and built-in horizontal scaling capability, made DynamoDB the clear choice for this project’s high concurrency and low-latency requirements. Amazon DynamoDB – The Core Database
DynamoDB emerged as the best fit for several reasons:
- High Availability and Scalability: With DynamoDB, we can automatically scale up or down based on traffic, and AWS manages the underlying infrastructure, ensuring availability across multiple regions.
- Serverless Architecture Compatibility: Since our application was API-first and serverless, built with AWS Lambda in Node.js and Python, DynamoDB’s seamless integration with AWS services suited this architecture perfectly.
- Flexible Data Model: DynamoDB’s schema-less, JSON-compatible structure aligned with our data requirements.
Read more about Amazon DynamoDB.
Extending with Sentiment Analysis: The DynamoDB and Elasticsearch Combo
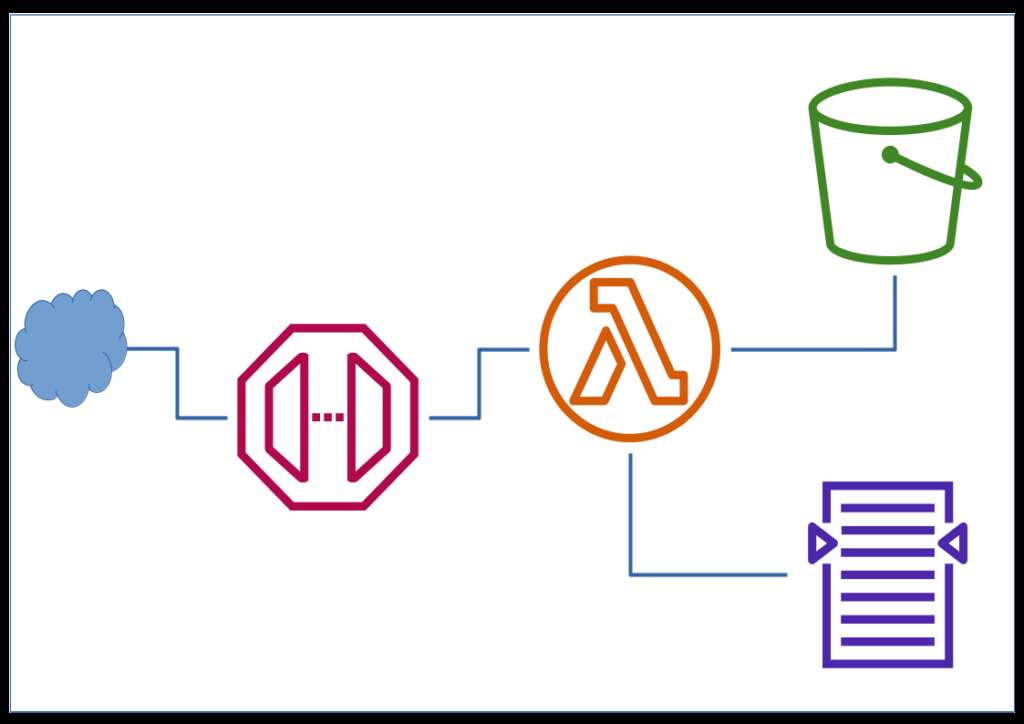
The project’s requirements eventually included sentiment analysis and scoring based on user reviews. Full-text search and analysis aren’t DynamoDB’s strengths, especially considering the potential cost of complex text scanning. So, we created a pipeline to augment DynamoDB with Amazon OpenSearch Service (formerly Elasticsearch Service), which can handle complex text indexing and full-text queries more cost-effectively.
- DynamoDB Streams: Enabled DynamoDB Streams to capture any changes to the data in real time. Whenever a new review was added, it triggered a Lambda function.
- Lambda Processing: The Lambda function post-processed the data, calculating preliminary sentiment scores and preparing it for indexing in Amazon OpenSearch Service.
- OpenSearch Indexing: The review data, now pre-processed, was indexed in OpenSearch for full-text search and analytics. This approach allowed efficient searching without burdening DynamoDB.
Read more about Amazon OpenSearch Service.
Leveraging Amazon S3 and AWS Athena for Historical Analysis
With time, the volume of review data would grow significantly. For long-term storage and further analysis, we used Amazon S3 as a durable and cost-effective storage solution. Periodically, the indexed data in OpenSearch was offloaded to S3 for deeper analysis using Amazon Athena.
- Amazon S3: Enabled periodic data archiving from OpenSearch, reducing the load and cost on OpenSearch. S3 provided a low-cost, durable storage solution with flexible retrieval options.
- Amazon Athena: Athena allowed SQL querying on structured data in S3, making it easy to run historical analyses and create reports directly from S3 data.
This setup supported large-scale analytics and reporting, allowing us to analyze review trends and user feedback without overburdening the application database.
Read more about Amazon S3 and Amazon Athena.
Final Architecture and Benefits
The final architecture leveraged AWS’s serverless services to create a cost-effective, high-performance database system for our application. Here’s a breakdown of the components and their roles:
- DynamoDB: Primary database for high-throughput, low-latency data storage.
- DynamoDB Streams & Lambda: Enabled real-time data processing and integration with OpenSearch.
- Amazon OpenSearch Service: Provided efficient full-text search and sentiment analysis.
- Amazon S3 & Athena: Archived data and performed large-scale, cost-effective analytics.
This combination of DynamoDB, OpenSearch, and S3, with Athena for analytics, proved to be an efficient architecture that met all project requirements. The AWS ecosystem’s flexibility allowed us to integrate services tailored to each specific need, maintaining cost-effectiveness and scalability.
- #DynamoDB #OpenSearch #AmazonS3 #AWSAthena #AWSLambda #Serverless #DatabaseSelection #CloudArchitecture #DataPipeline
This architecture and service setup provides a powerful example of how AWS’s managed services can be leveraged to achieve cost-effective performance and functionality.