For almost over the last decade ( since 2009 ), I was never worried about the EBS performance indexes. Used to create a single volume and attached to an instance as and when required. Today just for wandering, and to entertain myself, did a couple of tests. Thanks to aws-cli without which this could have taken more than what it would.
Straight into what I found in a short summary. Note that the values are Bps.
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | |
| Single | 272M | 492M | 268M | 1.3G | 393K | 272M | 8954.02M |
| Raid 0 | 631M | 671M | 740M | 1.3G | 366K | 631M | 8851.47 |
| Raid 5 | 336M | 250M | 332M | 1.2G | 9.9k | 315M | 8306.52 |
Kicked up an EC2 instance and mounted a 200gb EBS volume to run a series of tests. Thanks to nixCraft article titled “Linux and Unix Test Disk I/O Performance With dd Command“.
#!/bin/bash
dd if=/dev/zero of=/data/test1.img bs=1G count=1 oflag=dsync
rm -f /data/test1.img
dd if=/dev/zero of=/data/test2.img bs=64M count=1 oflag=dsync
rm -f /data/test2.img
dd if=/dev/zero of=/data/test3.img bs=1M count=256 conv=fdatasync
rm -f /data/test3.img
dd if=/dev/zero of=/data/test4.img bs=8k count=10k
rm -f /data/test4.img
dd if=/dev/zero of=/data/test4.img bs=512 count=1000 oflag=dsync
rm -f /data/test5.img
dd if=/dev/zero of=/data/testALT.img bs=1G count=1 conv=fdatasync
rm -f /data/test6.img
hdparm -T /dev/<device>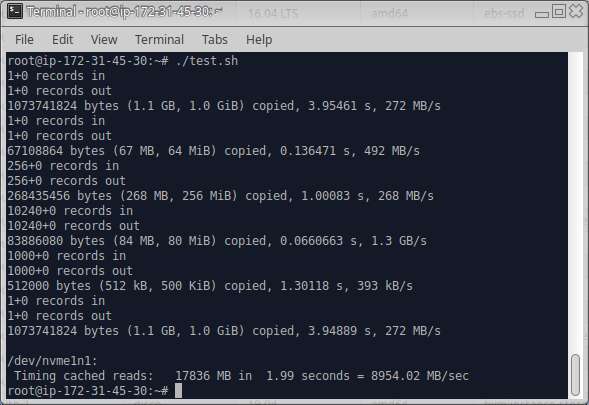
Well after that tore down removed the single ebs volume and deleted the same. Then created 12 20Gb ebs volumes. The listing in text mode was dumped into a text file and against each, a device id of pattern xvd[h-s] was added to the text. This was done just to further enable looping commands.
Then 10 20GB disks were attached to the instance, and internally this was assembled into /dev/md0 using raid level 0. The same test was run again and the output is as below.
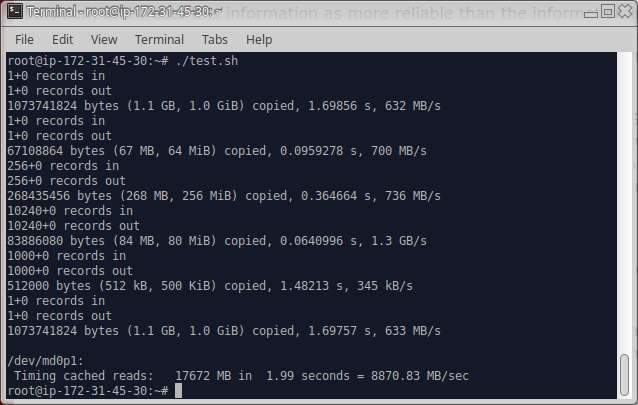
How good it seems but we are allocating too much, actually most of our major projects would not take more than a 100gigs and this was way toomuch. So thought about playing with it further.
The raid was stopped, unmounted and super-block erased using dd command. The next test was conducted with the same configuration only change was that I just added 5 disks this time.
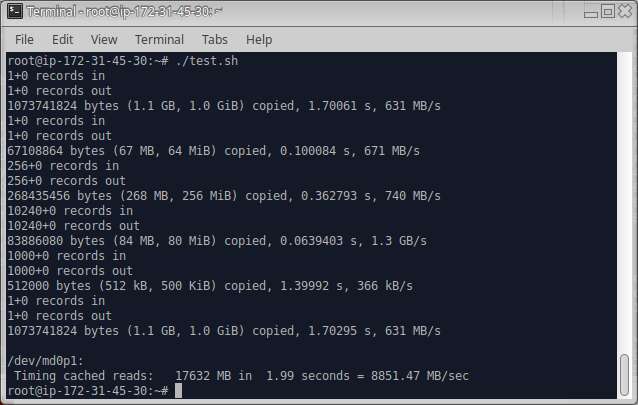
Ha! Ha.. not much of a degradation. I am still confused at this one, might be that we are having only 2VCPu in the vm. Sometime later I should attempt this with a different hardware.
But again thought about another option, why not try the raid5. Yes again did the cleanup, and added 6 of the volumes back to the same instance and did the same test.
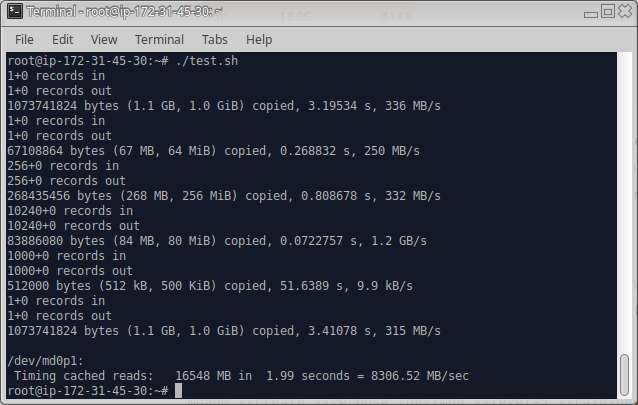
Aw!.. as expected the performance is dropped 🙁 might be due to the parity writing overhead.
As per the EBS Volume types document it is more or less 3 IOPS per GiB of volume size, with a minimum of 100 IOPS. This means the 200G allocates about 600 IOPs, raid 0 with 10 20G will give 1000 IOPs, raid0 with 5 x 20G will give 500, and the raid5 with 6×20 has 600 IOPs.
For a reference the commands which I used are illustrated below. The ami id used is from Ubuntu Amazon EC2 AMI Finder, for region ap-south-1, focal hvm.
# create instance
aws ec2 run-instances --image-id ami-06d66ae4e25be4617 --security-group-ids <sg-id> --instance-type m5.large --count 1 --subnet-id <subnet-id> --key-name <keyname>
# create volume attach and then finally cleanup
aws ec2 create-volume --availability-zone ap-south-1c --size 200
aws ec2 attach-volume --device xvdf --volume-id vol-058b551d8ce21e37d --instance-id i-04373f3985b1a13e6
aws ec2 detach-volume --volume-id vol-058b551d8ce21e37d --instance-id i-04373f3985b1a13e6
aws ec2 delete-volume --volume-id vol-058b551d8ce21e37d
# create 12 identical volumes
seq 1 12 | while read i; do aws ec2 create-volume --availability-zone ap-south-1c --size 20; done
# find those volumes which are available
aws ec2 describe-volumes --output text | grep available
# vol-071e9b06c24627554 xvdh
# vol-0097f6ee4b1f0f614 xvdi
# vol-05a882cefed9a8c13 xvdj
# vol-0cf57aab66e51c68b xvdk
# vol-075ab760f2df2270c xvdl
# vol-073b272e1f84b4450 xvdm
# vol-0c98e527a16d34764 xvdn
# vol-0603e3976cd6f0c34 xvdo
# vol-0c488b59b353d51bd xvdp
# vol-05a04ea90f18d52ff xvdq
# vol-0a8726c93947641e2 xvdr
# vol-08903b57f0d5518d0 xvds
# take 10 volumes from the list and attach them
head -10 vols | while read vol dev; do aws ec2 attach-volume --device $dev --instance-id i-04373f3985b1a13e6 --volume-id $vol ; done
# create raid, create partition, format and mount
mdadm -C /dev/md0 -l raid0 -n 10 <list of devices>
fdisk /dev/md0 [p, enter 3 time, wq]
mkfs.ext4 /dev/md0p1
mount /dev/md0p1 /data
** run tests
# unmount, stop raid, write zeros into the first 12M (clears partition and super-block)
umount /data
mdadm --stop /dev/md0
seq 1 10 | while read f; do dd if=/dev/zero of=/dev/nvme${f}n1 bs=12M count=1; done
# detach volumes
head -10 vols | while read vol dev; do aws ec2 detach-volume --instance-id i-04373f3985b1a13e6 --volume-id $vol ; done
# final cleanup
cat vols | while read vol dev; do aws ec2 delete-volume --volume-id $vol ; done
aws ec2 terminate-instances --instance-id i-04373f3985b1a13e6