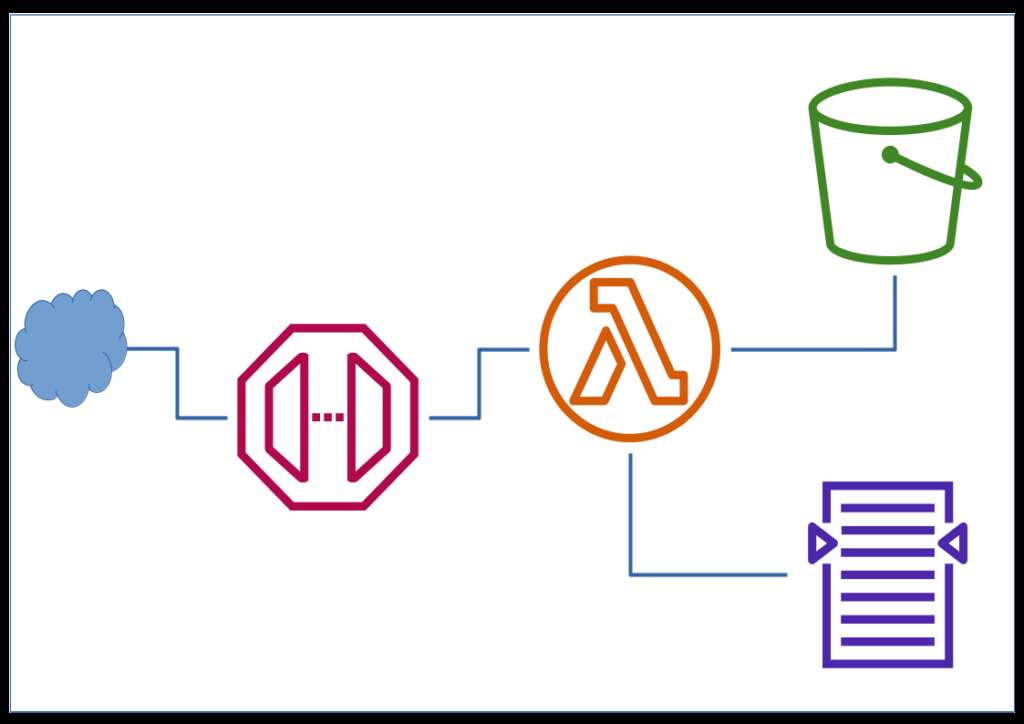
Reference architecture for a generic interface for Cloud Search on AWS with a broker in any lambda-supported runtime. For the particular implementation, I chose and used Node.js. Hence any client request is authorized from an API key and hits the aws api gateway which in turn invokes the lambda function. In this function internally the code will do necessary normalization and pass it on to aws Cloud Search and if any response the same is reformatted for adapting as aws api gateway response. Along with this functionality, the lambda broker will write a human-readable version of the request as analyzed from the request with request method as verb keywords and sort direction with a prefix of JSON property names, etc into AWS cloud watch with simple console.log methods. Tried to make it as generic as possible.
An event bridge scheduler will trigger another lambda which will analyze these human readable messages and try to detect any missing indexes which will be auto-created into the Cloud Search and updated into a config file on aws S3. Lots of production testing and fine tuning is pending along with necessary documentation as well as the AWS sam template to deploy the same. As of now, this is just a blueprint and the components are lying in different locations and need orchestration there are no plans to open this on any public repository. But anyone who wants to adopt the design is free to pick this and do it on his own without any commitment to me. By creating this with the self-learning capabilities this system can be used literally by many applications even those that already depend on some kind of custom clumsy backend.
A few real-time use cases could be community member databases, hospital patient records, pet shops and many more. Generally, the request methods should work like POST create a new record, PUT updates a record, DELETE deletes ( or trash ) a referenced record, and GET fetch according with proper documentation the feature can be defined as the client software is designed and developed.
The reference architecture drawing is attached here and that is just my thoughts. Please share if you think this is good enough.